Otimize seu Delta Lake e reduza custos (Storage, Databricks e computação)
- Reginaldo Silva
- 28 de jan. de 2023
- 5 min de leitura
Atualizado: 30 de jan. de 2023
Fala pessoal, esse post é para galera do Delta lake. Se você utiliza tabelas no formato Delta no seu Data Lake então, sim, é para você mesmo.
Estou disponibilizando um script que vai te auxiliar nas suas manutenções e customizar suas rotinas de manutenção e pode te trazer muitos benefícios desde melhoria de performance nas suas queries até mesmo redução de custo com Storage.

Vamos la, deixa eu contextualizar um pouco sobre o delta, mas sem entrar a fundo, na demonstração vocês irão entender melhor, não irei abordar aqui sobre conceitos de Lakehouse ou Data Lake, focarei na prática.
As suas tabelas Delta que estão armazenadas no seu Data Lake (ou Storage rs) tem 2 comportamentos que podem prejudicar a sua performance e custo:
1 - Histórico de versões e VACUUM
Tabelas com grande quantidade de modificações como INSERT, UPDATE, DELETE, MERGE, essas operações fazem com que sua tabela seja versionada, em outras palavras, tudo que você altera na sua tabela é gerado uma versão nova e a antiga fica disponível e você pode navegar nela, é o famoso TIME TRAVEL. Esse recurso sem dúvidas é maravilhoso, até mesmo para troubleshooting ou restore de manutenções aplicadas incorretamente, contudo, as tabelas DELTA padrão não possuem limpeza dessas versões, ou seja, é armazenada infinitamente, logo se sua tabela tem muita modificação seu storage vai crescer exponencialmente, simples assim.
Então seu papel como responsável por aquela tabela é definir uma rotina de VACUUM, essa operação limpa as versões não ATUAIS definitivamente do Storage, você pode definir quanto tempo quer limpar, o recomendado é que você mantenha pelo menos 7 dias, há casos em que não há essa necessidade e você pode colocar 24 horas, mas, cada caso é um caso, lembre que depois que rodar o VACUUM com 24 horas, todos os históricos mais antigos que 24 horas serão perdidos e você perderá o TIME TRAVEL nesse dado. Bom, mas pense aí, até que ponto vale armazenar históricos no seu caso? Você faz analises dessas versões?
Já peguei casos com uma tabela ter 10 TB de logs e apenas 50 GB de dados, faz muito sentido não ne? Ja imaginou o quanto de storage estava sendo pago?
"Reginaldo, como posso saber quanto espaço essas versões estão ocupando?"
A forma mais simples é, vá no storage na pasta da tabela, some o total de espaço ocupado e desconte o tamanho atual da tabela que fica no campo sizeInBytes quando voce roda o comando "Describe detail", veremos mais abaixo.
Esse cálculo vai te dar um retorno aproximado, em breve irei disponibilizar um script para facilitar isso integrado com essa rotina de manutenção.
Ref:
2 - Problema de muitos arquivos pequenos
Esse é um problema muito comum em arquiteturas de Data Lakes, tabelas com muitos arquivos pequenos impactam drasticamente na performance das suas consultas. Para isso você pode rodar o comando OPTIMIZE para agrupar os pequenos arquivos em arquivos maiores e assim, melhorando sua performance, note que estou sendo simplista e direto, existe uma série de técnicas e parâmetros que podemos entrar nesse tema.
Com o OPTIMIZE você pode também especificar o ZORDER, ele ordena as informações pelo campo escolhido e mantém na sequência dentro do mesmo arquivo, ajudando operações de Data-Skipping e reduzindo a quantidade de dados lida (Pense no ZORDER como se fosse um índice de banco de dados relacional).
Olha, isso realmente faz uma grande diferença, e você deve me perguntar "Ah Reginaldo, de quanto em quanto tempo devo rodar?" e minha resposta como um bom sênior é: Depende. rs
Brincadeiras a parte, não há uma forma simples de ver quanto a tabela estaria "fragmentada" com o tempo, o ideal é ir testando, monitorando, encontrar um ponto no seu baseline que faça sentido, exemplo 1 vez por semana, ou até mesmo 1x por dia.
Ref:
Esse script que está no meu Github te ajudará a automatizar a manutenção nas suas tabelas e melhorar sua performance e custo com storage. Vou deixar uns prints de exemplo, mas tudo está no github, links no final do post.
Entretanto, há uma exceção onde isso não há necessidade: DLT
Isso mesmo, se você usa Delta Live Tables você já tem esses benefícios, mas se liga, você pode alterar esse comportamento se quiser.

Vamos lá! Preparei um ambiente bem simplão para que você possa testar aí também, atente-se apenas a trocar o caminho na operação de WRITE, estou usando um Mount(mnt\raw) que criei para teste. Os dados de testes já estão no seu Databricks, isso mesmo, na pasta de /Databricks-Datasets, não fui eu quem copiei aí não rs, já vem por padrão com muitos outros exemplos para brincar.
Vamos executar alguns Updates (12 no total) só para gerar algumas versões na nossa tabela Delta. Essa tabela tem pouco mais de 5 mil registros.

Note que a tabela atual possui apenas 1 arquivo, ou seja, todos os dados estão apenas nesse arquivo, isso devido a nossa tabela ser bem pequena.
Coluna numFiles: Quantidade de arquivos na versão atual da tabela, não conta as versões históricas.

Com o comando Describe History você pode ver todas as versões e navegar por elas, o famoso TIME TRAVEL se traduz em "select * from db_festivaldemo.PatientInfoDelta AS VERSION OF 10", nessa query estou olhando para a versão 10 da tabela, como ela estava naquele momento do tempo, isso é sensacional para analisar como estava uma informação no passado (Isso ainda continua sendo diferente de CDF\CDC change data capture), posso usar também para operação de Restore.
Temos 12 versões devido a termos feito 12 Updates na primeira célula do notebook, logo, para cada UPDATE temos uma nova versão, sendo a versão 12 a versão mais recente e atual da tabela, é a versão que todos vão enxergar sem usar o TIME TRAVEL.

Mas, vamos lá, o TIME TRAVEL não é só flores, lembra que na versão atual da tabela temos apenas 1 arquivo, mas aqui num count bem simples ele retorna 13 (14 - 1 da pasta delta_log), logo, 12 desses arquivos não fazem mais parte da nossa tabela e estão consumindo espaço desnecessário (Considerando que não uso o Time Travel), pense nisso em tabelas bem movimentas, facilmente chega a Terabytes (TB) de logs isso.
Só para esclarecer o comando, estou fazendo um COUNT de quantidade de arquivos na pasta da nossa tabela Delta, ele retornou 14 como pode ver no print, sendo 13 são arquivos e 1 é uma pasta do delta_log, desses 13, 1 arquivo é da versão atual e 12 arquivos são históricos dos Updates, logo cada Update criou um novo arquivo. Não se preocupe se não ficou tão claro o funcionamento da engine, é bem difícil explicar em um texto sem ser tão extenso, em breve falarei mais sobre isso.

Então vamos para o remédio, baixe o notebook, coloque na sua pasta e instancie ele com o comando RUN, apenas corrija o caminho para a sua pasta.
Esse comando gera uma instância de todas as funções e variáveis do notebook para dentro do seu.

Antes de executar de fato, você pode preencher o parâmetro debug=True, isso apenas irá printar as ações que irão ocorrer, famoso WhatIf.
Aqui já estamos utilizando a função criada maintenanceDeltalake e passando alguns parâmetros para ela.

Agora, sim, parâmetro debug=False, o Vacuum setado para 0 horas (apenas para teste), ou seja, limpar todas as versões da tabela delta e aplicar o Optimize com Zorder nas colunas sex e patient_id.
Note que na tela vai aparecendo detalhes de cada operação, com o comando executado e a hora de início e fim, vai por mim, esses logs são úteis.

"Ah Reginaldo, eu não uso o catalogo do Hive", sem problemas, informe no parâmetro nomeSchema='delta' e informe o caminho da tabela delta no seu storage dentro ``, também funciona.
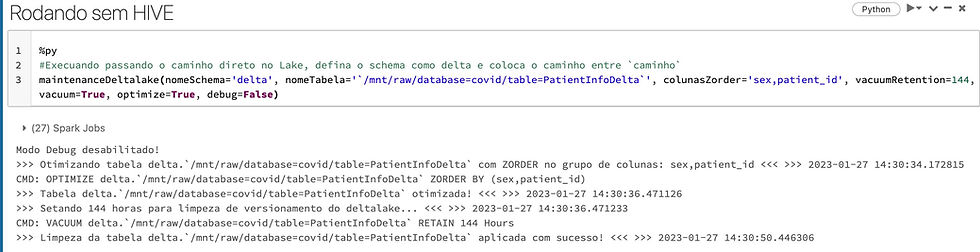
E é isso, agora nossa pasta do Storage tem apenas 1 arquivo que é o arquivo atual da tabela, contudo, sem a opção de TIME TRAVEL também, então defina sua estratégia de limpeza, o recomendado é 7 dias, mas não se prenda a isso.

Não menos importante, os códigos:
Existem muitas outras técnicas de performance tuning, se possível abordarei mais algumas, quem sabe alguns vídeos para o Databricks 0 a 100, talvez mostrar o ZORDER na prática com um caso real.
Espero que te ajude.
Fique bem e até a próxima.
Commenti