IA & Agentes
Copilot Studio do zero [4] - Evaluation: será que seu agente responde bem? (o meu tirou 40%)
![Copilot Studio do zero [4] - Evaluation: será que seu agente responde bem? (o meu tirou 40%)](/images/copilot-dataday-eval-capa.png)
Fala dataholics, bora de mais conteúdo técnico! Essa é a parte 4 da nossa série Copilot Studio do zero. No post anterior a gente criou o DataDay, aquele agente que responde sobre o calendário da empresa. Eu testei na mão, ele respondeu certinho os eventos de janeiro e a sensação foi de "tá pronto, pode publicar".
Aí eu fiz a pergunta que todo mundo devia fazer antes de soltar um agente pro mundo: será que ele responde bem SEMPRE? Testar 2 ou 3 perguntas na mão não prova nada. Bora medir isso de verdade com o Evaluation do Copilot Studio. Spoiler do resultado: o DataDay tirou 40%. E foi a melhor coisa que podia ter acontecido.
O que veremos nesse post:
O que é Evaluation (e por que é teste de regressão pra agente)
Como criar uma evaluation: os tipos e as fontes de perguntas
Rodando e lendo o score
Um Pass por dentro: os 3 checks de qualidade
Um Fail por dentro: o "Not answered" que me ensinou muito
Boas práticas e o que dá pra corrigir
Resumo
O passo a passo está no vídeo abaixo. Como sempre, o vídeo é sem narração, só a gravação da tela. A explicação de verdade está aqui no post.

O que é Evaluation
Pensa no Evaluation como o teste de regressão do seu agente. Em vez de você ficar digitando pergunta por pergunta na mão, você monta um conjunto de perguntas (um Test Set), roda tudo de uma vez e um LLM juiz avalia cada resposta, dando Pass ou Fail e um score geral.
Por que isso importa? Porque agente é coisa viva: você mexe nas Instructions, troca a fonte de Knowledge, ativa uma tool, e sem querer quebra algo que funcionava. Com um Test Set salvo, é só rodar de novo depois de cada mudança e ver se melhorou ou piorou. Sem isso, "meu agente está bom" é achismo.
Criando uma evaluation: tipos e fontes de perguntas
Na aba Evaluation você clica em New evaluation e cai nessa tela. Tem duas decisões pra tomar: o Data type e a fonte das perguntas.
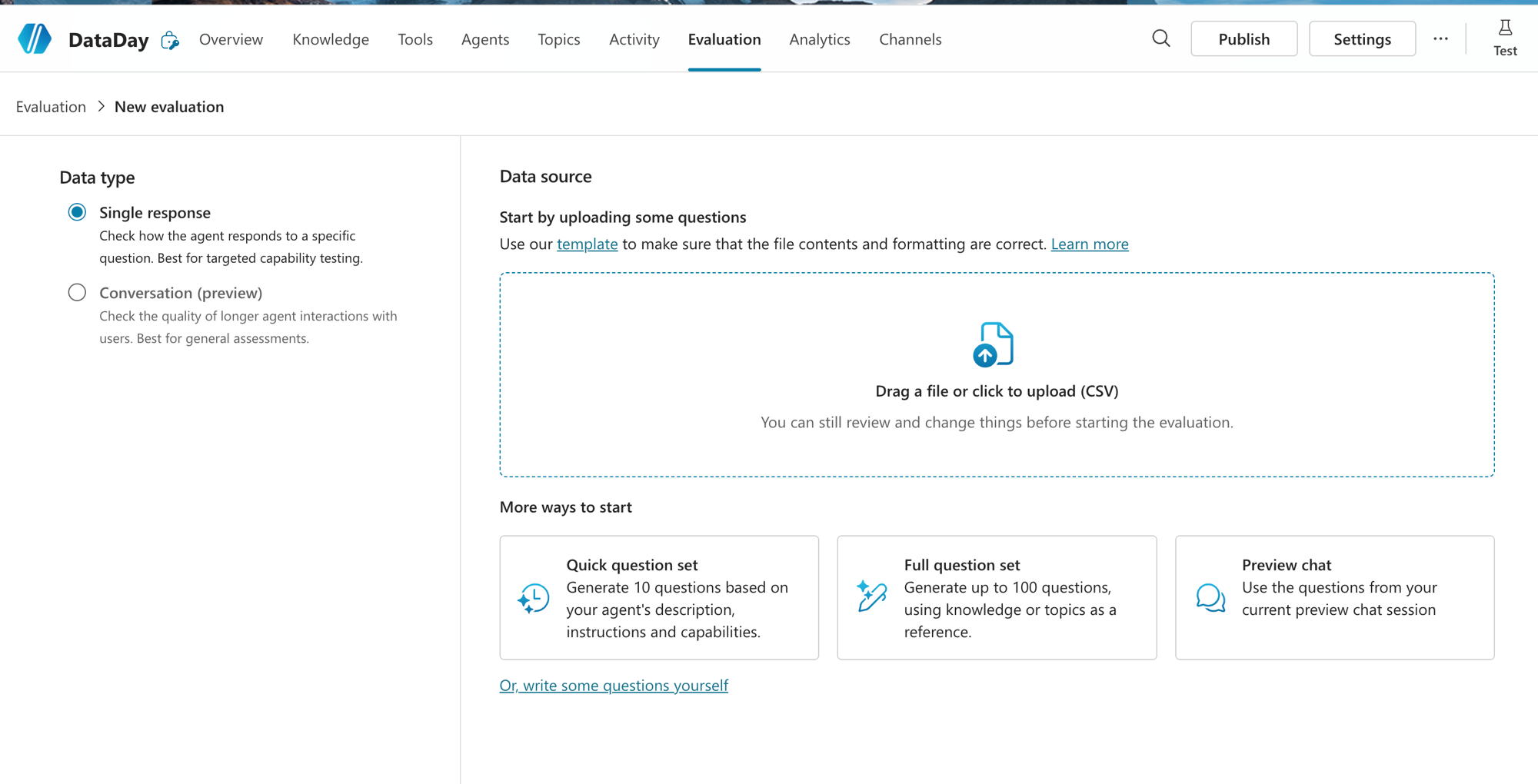
No Data type você escolhe entre:
Single response: avalia a resposta a uma pergunta isolada. É o "capability testing" pontual, ideal pra checar se ele acerta cada tipo de pergunta. Foi o que eu usei.
Conversation (preview): avalia a qualidade de uma conversa mais longa, com várias trocas. Melhor pra avaliação geral, quando o contexto de mensagens anteriores importa.
Já na fonte das perguntas, o Copilot te dá vários caminhos:
Upload de CSV: você sobe suas próprias perguntas (tem um template pronto pra baixar e não errar o formato).
Quick question set: gera 10 perguntas automaticamente a partir da descrição, das instructions e das capacidades do agente.
Full question set: gera até 100 perguntas usando o Knowledge e os Topics como referência.
Preview chat: aproveita as perguntas da sua sessão de teste atual.
Ou escrever as perguntas você mesmo, na unha.
Reginaldo, qual dessas eu escolho?
Vou ser honesto com você: nesse teste eu não montei nada na mão. Cliquei no Quick question set e deixei o Copilot gerar as 10 perguntas automaticamente, em segundos. E aí mora parte da explicação do meu 40%: algumas dessas perguntas geradas não estavam aderentes aos dados do calendário, pediam coisa que nem existe na planilha, então o agente ia falhar de qualquer jeito. Serve de lição: o Quick question set é ótimo pra dar o pontapé, mas o melhor dos mundos é você criar as perguntas reais, com base no que os usuários vão de fato perguntar (com gíria, sem data exata, ambíguas). Comece com o gerador, evolua pro seu próprio conjunto.
Rodando e lendo o score
Depois de montar, seu Test Set fica salvo (dá pra reusar quantas vezes quiser) e cada execução aparece em Recent results com o score. Olha aqui: o Test Set Evaluate DataDay com 10 test cases, e a última rodada com General quality de 40%.
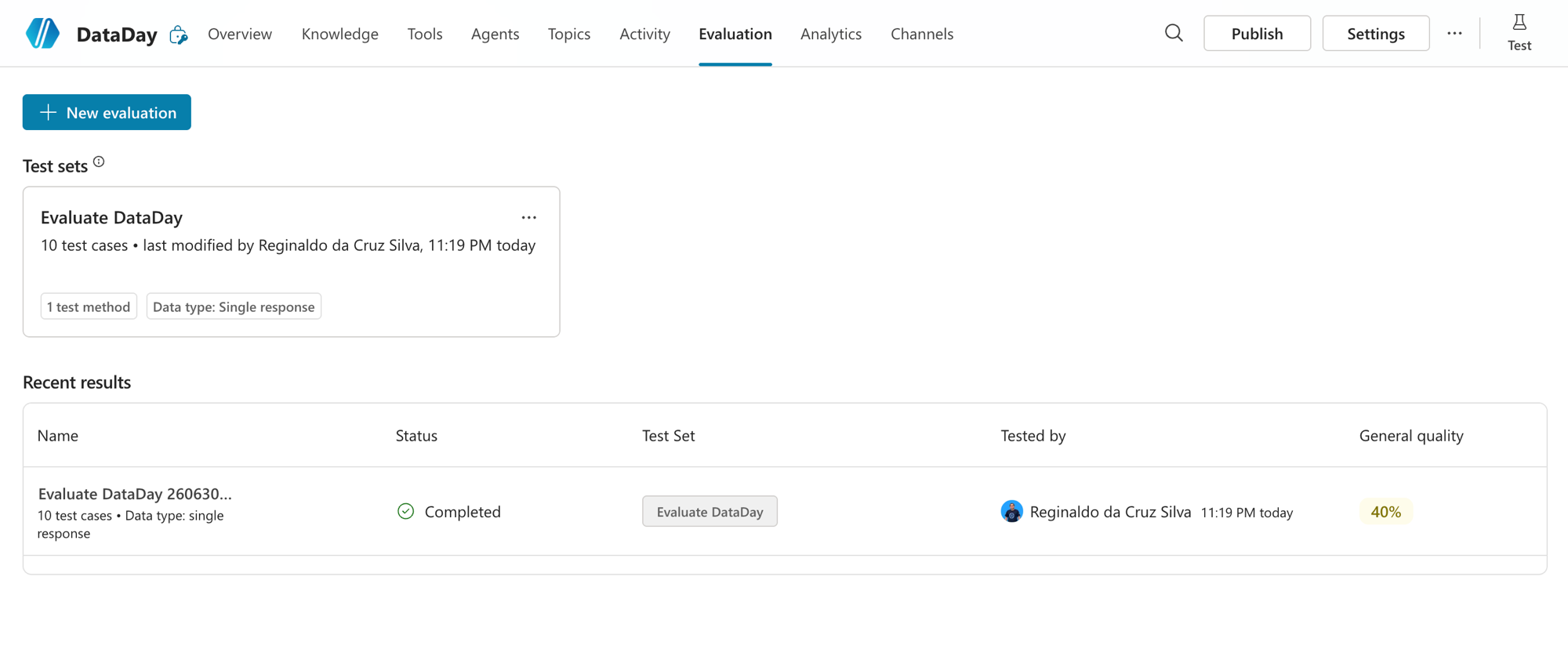
Abrindo o resultado, a coisa fica visível: 4 Pass e 6 Fail. Cada linha mostra a pergunta, a resposta do agente e o veredito. E dá pra filtrar só os Pass ou só os Fail, que é onde mora o aprendizado.
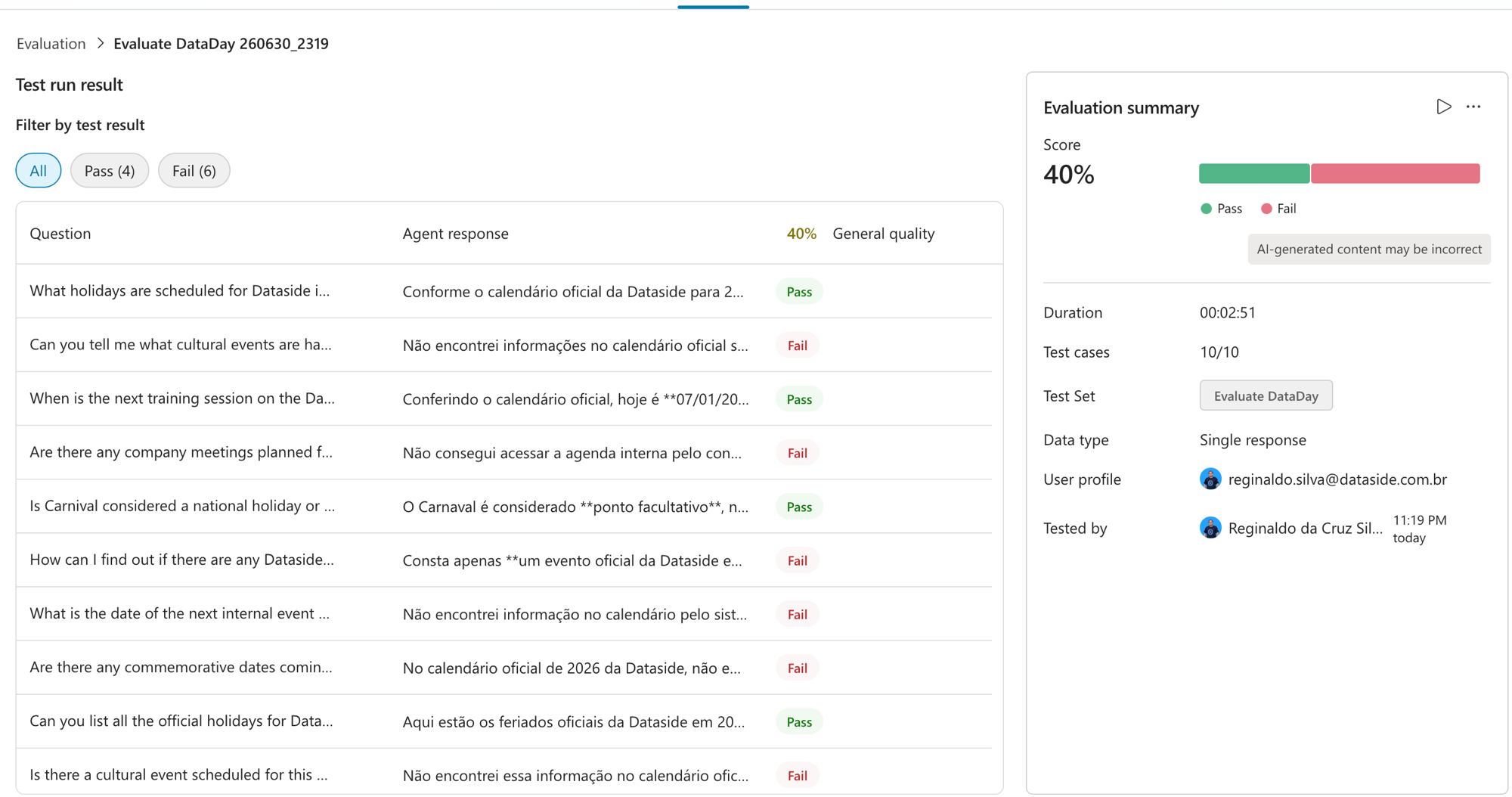
Repara num padrão logo de cara: as perguntas sobre feriados (fatos estáticos, que estão listados na planilha) passaram. As perguntas sobre "essa semana", "próximo evento", "eventos culturais deste mês" falharam. Guarda isso, porque é a chave do diagnóstico.
Um Pass por dentro: os 3 checks
Clicando num caso que passou (a pergunta "What holidays are scheduled for Dataside in 2026?"), o painel Test case details explica o porquê do Pass:
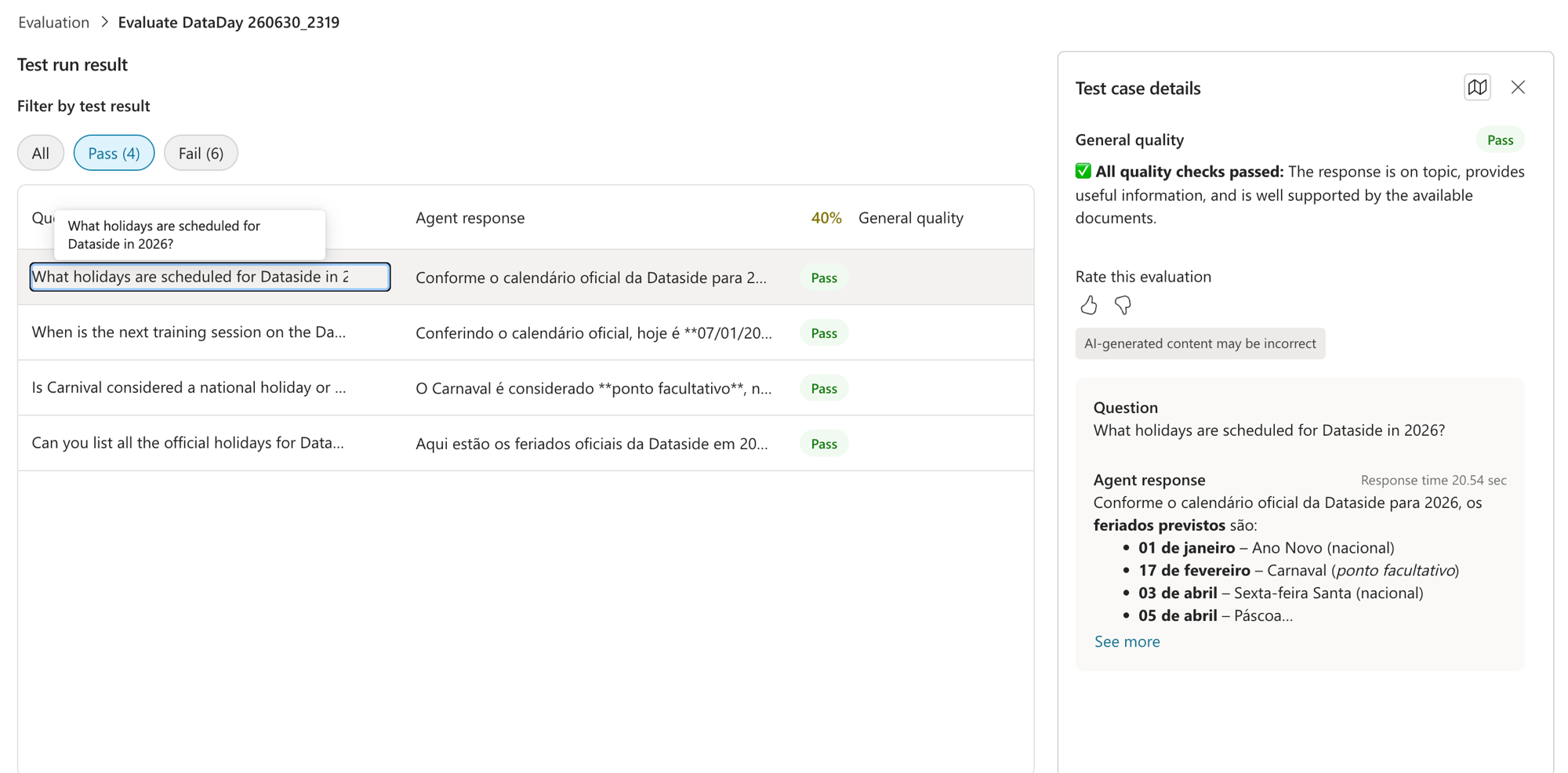
O juiz diz "All quality checks passed" e destrincha o critério: a resposta está no tema (relevance), traz informação útil e completa (completeness) e está bem embasada nos documentos disponíveis (use of knowledge sources). Esses são os 3 eixos que ele mede. O DataDay respondeu a lista de feriados com data e ainda separou nacional de facultativo, exatamente como pedimos nas Instructions. Pass merecido.
Um Fail por dentro: o "Not answered"
Agora o ouro do post. Clica no Fail da pergunta "Can you tell me what cultural events are happening this week?". Olha o veredito:
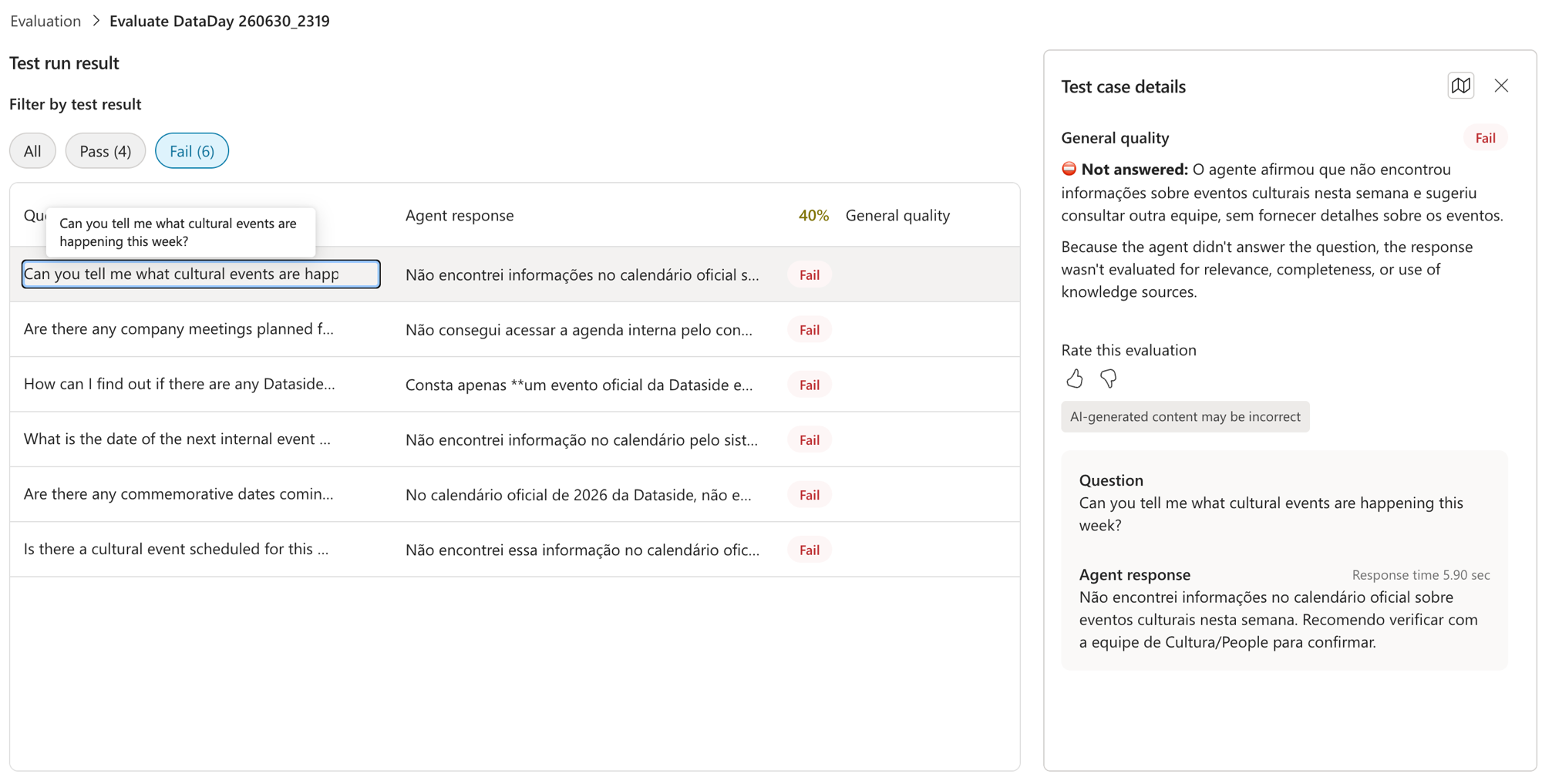
O agente respondeu: "Não encontrei informações no calendário oficial sobre eventos culturais nesta semana. Recomendo verificar com a equipe de Cultura/People." E o juiz marcou como Not answered: "o agente afirmou que não encontrou e sugeriu outra equipe, sem fornecer detalhes". Como ele não respondeu, nem foi avaliado por relevância ou completude. Fail seco.
E aqui vem a lição que vale o post inteiro: esse Fail não é o agente alucinando, é o contrário. Lembra que nas Instructions eu mandei "se não estiver no calendário, diga que não consta e mande procurar o time de Cultura"? Essa regra, que é ótima pra evitar invenção, disparou na hora errada. A empresa TEM eventos culturais no calendário. O que faltou foi o agente recuperar essa informação, porque a pergunta pedia raciocínio de data ("esta semana") e o DataDay não tem uma tool de data confiável nem soube filtrar o período.
Ou seja, a evaluation revelou dois problemas reais que o teste na mão escondeu:
Raciocínio de tempo relativo: "essa semana", "próximo", "este mês" exigem saber a data de hoje e filtrar. Sem uma tool de data, o agente se perde.
Recuperação de eventos internos: em várias perguntas ele disse "não consegui acessar a agenda interna". Isso é gap de Knowledge/grounding, não de comportamento.
O detalhe cruel: uma instrução de segurança ("não invente, diga que não sabe") transformou uma falha de busca numa não-resposta educada, que o juiz conta como Fail. Se eu não tivesse rodado a evaluation, publicaria um agente que responde "procura o time de Cultura" pra 6 de cada 10 perguntas reais. Dá pra imaginar a frustração do usuário.
Boas práticas (e o plano de correção)
O que eu levo dessa rodada, e que serve pro seu agente também:
Comece com o gerador, mas evolua pra perguntas reais. Eu usei o Quick question set (10 perguntas automáticas) e parte do meu 40% veio de perguntas que nem batiam com os dados. Perguntas curadas por você, refletindo o que o usuário vai perguntar de verdade, dão um sinal muito mais honesto da qualidade.
Salve o Test Set e rode a cada mudança. É seu teste de regressão. Mexeu nas Instructions? Roda de novo e compara o score.
Leia os Fail um a um. O score é o sintoma, o painel de detalhes é o diagnóstico. Foi lendo os Fail que eu descobri que o problema era retrieval e data, não a "personalidade" do agente.
Cuidado com instruções de segurança agressivas. "Diga que não sabe" é bom contra alucinação, mas se a recuperação estiver fraca, ela mascara o problema em vez de resolver.
O plano pra subir esse 40%: adicionar uma tool de data pra resolver "esta semana/próximo", reforçar a recuperação dos eventos internos no Knowledge (e checar se o Web Search estava atrapalhando, como vimos no post 3), e depois rodar a mesma evaluation de novo pra provar que subiu. Antes e depois, no número.
RESUMO
Evaluation é o teste de regressão do agente: um Test Set roda várias perguntas de uma vez e um LLM juiz dá Pass/Fail com score.
Data type: Single response (pergunta isolada) ou Conversation (conversa longa).
Fonte das perguntas: CSV próprio, Quick set (10), Full set (até 100), Preview chat ou escritas na mão. Comece rápido com o Quick set, mas evolua pra perguntas reais.
O juiz mede 3 coisas: relevância, completude e uso das fontes de conhecimento.
Meu DataDay tirou 40%: passou nos feriados (fatos estáticos) e falhou em tempo relativo ("essa semana") e recuperação de eventos internos.
Um Not answered conta como Fail: uma instrução de "não invente" mal calibrada virou não-resposta e mascarou uma falha de retrieval.
Salve o Test Set, leia os Fail um a um e rode de novo depois de cada ajuste.
Moral da história: um agente sem evaluation é só achismo com UI bonita. Foi o "fracasso" de 40% que me mostrou exatamente o que consertar, e isso vale mais que qualquer teste manual que dava tudo verde.
No próximo post da série a gente continua evoluindo o DataDay. Bora juntos!
Referências:
https://learn.microsoft.com/en-us/microsoft-copilot-studio/analytics-evaluations
https://learn.microsoft.com/en-us/microsoft-copilot-studio/fundamentals-what-is-copilot-studio
Fique bem e até a próxima.
#copilotstudio #microsoftai #evaluation #agentes #ia #powerplatform #datainaction
Gostou? Tem mais no YouTube e no LinkedIn.