IA & Agentes
Copilot Studio do zero [5] - De 40% a 90%: consertando o agente com Evaluation
![Copilot Studio do zero [5] - De 40% a 90%: consertando o agente com Evaluation](/images/copilot-dataday-90-capa.png)
Fala dataholics, bora de mais conteúdo técnico! Essa é a parte 5 da nossa série Copilot Studio do zero, e é o fechamento da nossa introdução básica. No post anterior eu rodei o Evaluation no DataDay e ele tirou 40%. Prometi que ia consertar e provar a melhora no número. Pois é: cheguei a 90%, e o melhor, sem trocar o modelo de IA nem reescrever o agente do zero.
Mudei 3 coisas no total, entre o agente e a forma de testar. Bora ver o que move o ponteiro de verdade.
O que veremos nesse post:
A jornada em números: de 40% a 90% (não foi linear)
Alavanca 1: a tool de data (resolver "esta semana", "próximo")
Alavanca 2: desligar o Web Search
Alavanca 3: ajustar o set de perguntas (um teste honesto)
O resultado e o 1 Fail que sobrou
A lição de ouro
Resumo
A jornada em números
Antes de tudo, um detalhe que eu adoro do Evaluation: cada rodada fica salva em Recent results, então dá pra ver a evolução ao longo do tempo. E olha que honesto o meu histórico:
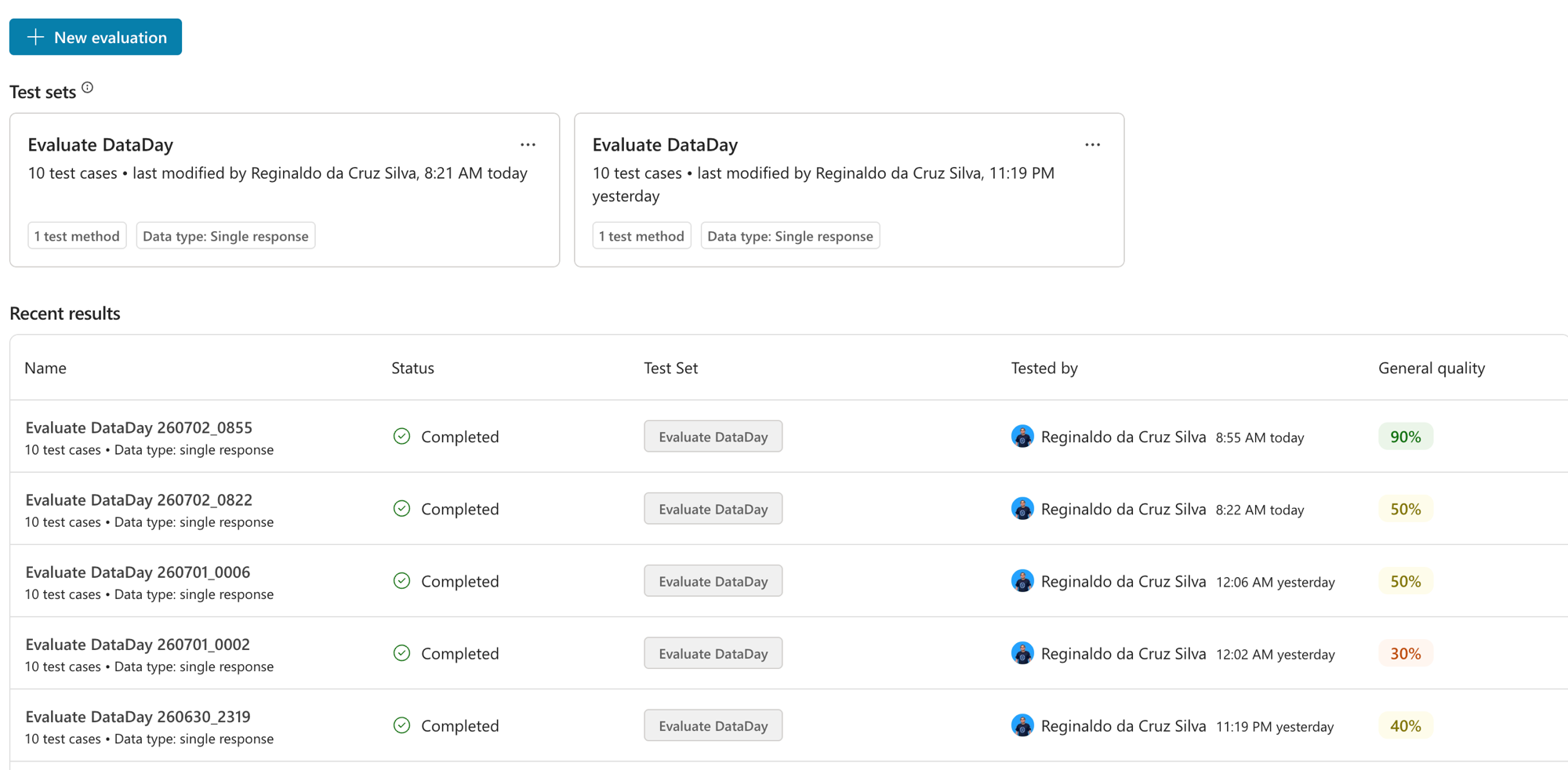
Repara que não foi uma linha reta: comecei em 40%, uma tentativa até me deu 30% (piorei!), depois 50%, 50% e finalmente 90%. Isso é o normal de ajustar agente: você muda uma coisa, mede, às vezes regride, entende o porquê e ajusta de novo. Sem o Evaluation salvo, eu estaria adivinhando se melhorei ou piorei. Com ele, cada mudança tem um número do lado.
Um bônus: dá pra usar o Compare with pra colocar duas execuções lado a lado e ver exatamente qual pergunta virou de Fail pra Pass. É o seu diff de qualidade.
Alavanca 1: a tool de data
Lembra que no post 4 os Fails eram perguntas com tempo relativo? "eventos desta semana", "próximo Culture on the Road". O agente não sabia nem que dia era hoje. A solução foi criar um Agent flow simples, que eu chamei de diaatual, com uma única missão: retornar a data de hoje.
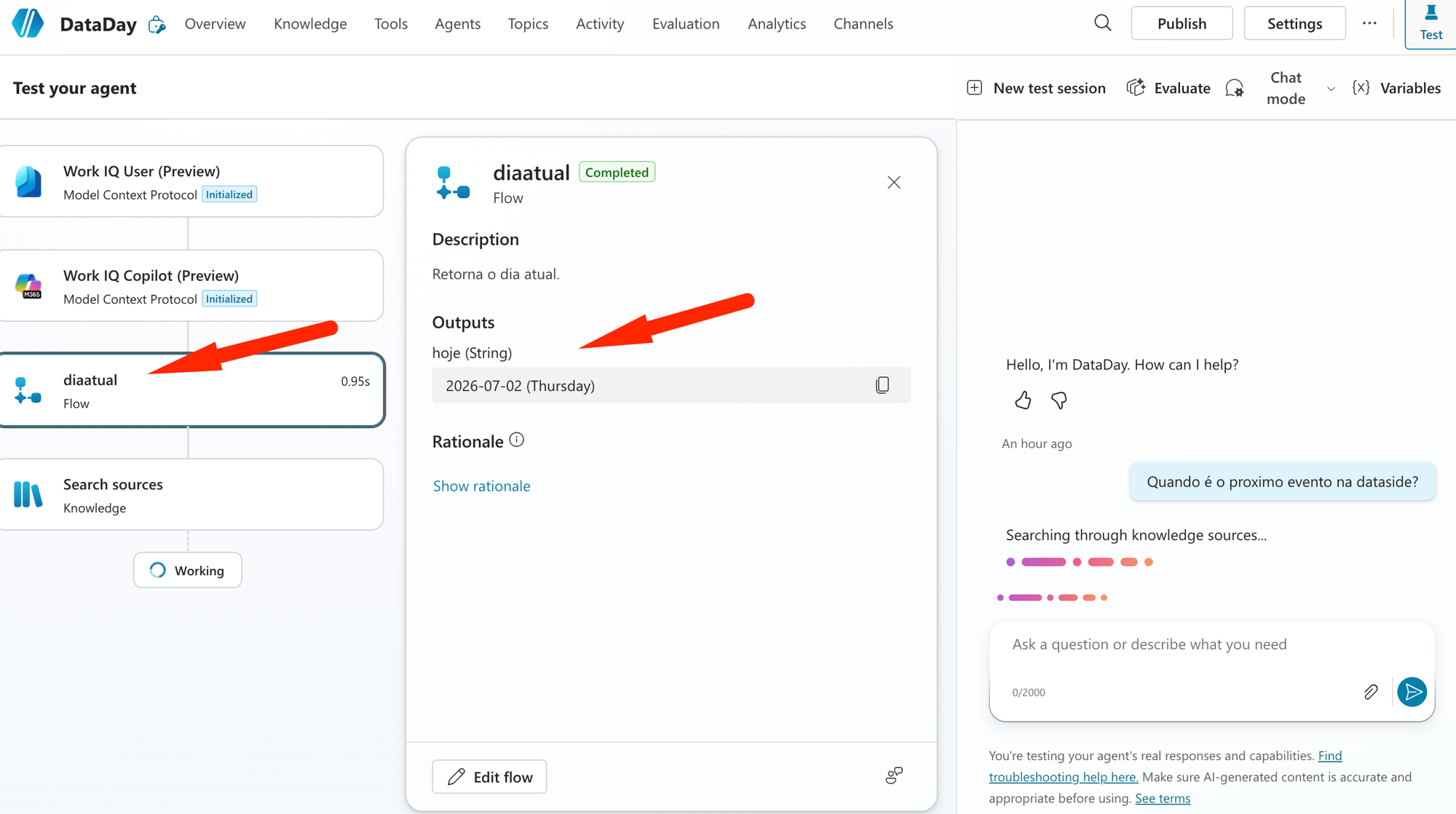
O segredo está na expressão. A função que retorna a data não aparece buscando "today", o nome dela é utcNow(). E como ela devolve em UTC, eu converto pro fuso do Brasil pra não errar o dia:
convertFromUtc(utcNow(), 'E. South America Standard Time', 'yyyy-MM-dd')No print, o output hoje voltou certinho: 2026-07-02 (Thursday). Agora, sempre que alguém pergunta algo com "hoje", "esta semana" ou "próximo", o agente chama essa tool primeiro e passa a raciocinar a partir da data real.
Reginaldo, e o agente sabe QUANDO chamar a tool?
Só se você mandar. Eu deixei explícito nas Instructions: "para qualquer pergunta com tempo relativo, chame a tool de data antes de responder". Sem essa regra, ele às vezes nem aciona a ferramenta.
Alavanca 2: desligar o Web Search
No post 3 eu já tinha percebido o Web Search se intrometendo, trazendo "eventos do Rio" de sites públicos no meio das respostas. Para um agente que responde sobre o SEU calendário, isso é ruído puro (e risco de data errada).
A correção é um clique: no bloco Knowledge, Web Search: Disabled. E não é só estética: com a web fora do caminho, o agente para de dividir a atenção com a internet e foca na fonte oficial, o que ajudou bastante na recuperação dos eventos internos.
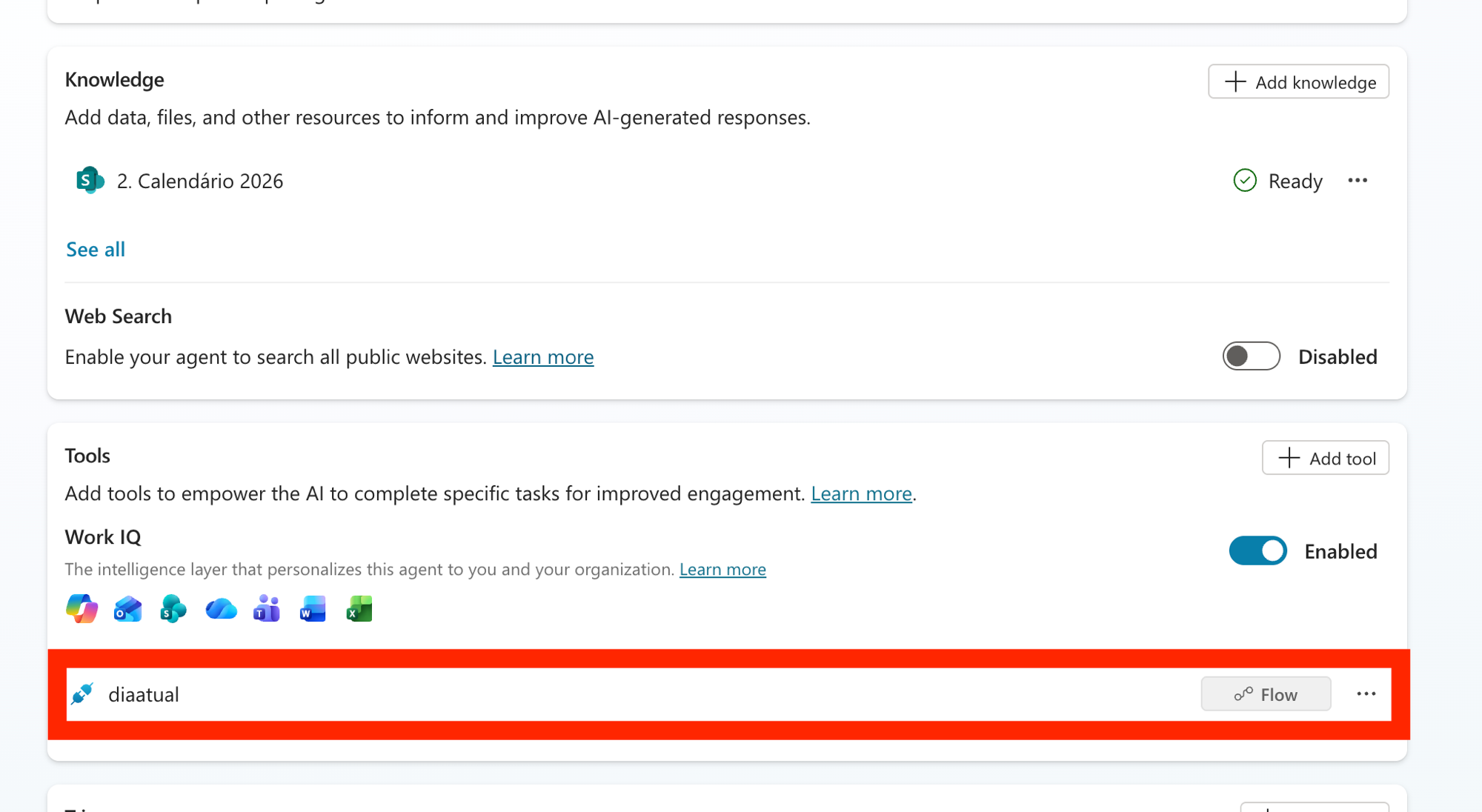
Nesse print de configuração dá pra ver o combo montado: o Knowledge do calendário (o mesmo Excel de sempre, eu não troquei a fonte) marcado como Ready, o Web Search Disabled e, nas Tools, o Work IQ ligado junto com a tool diaatual.
Alavanca 3: ajustar o set de perguntas (um teste honesto)
Essa alavanca é sobre o TESTE, não sobre o agente, e faz toda a diferença. Lembra que no post 4 eu deixei o Quick question set gerar as 10 perguntas automaticamente? Parte daquele 40% veio de perguntas que nem batiam com os dados do calendário: o agente ia falhar de qualquer jeito porque perguntavam coisa que não existe na planilha.
Então eu revisei o test set e troquei por perguntas reais e coerentes com o calendário, do jeito que um funcionário perguntaria de verdade: feriados, Festa Junina, próximo Culture on the Road, eventos do mês, Encontro de Mentores em setembro. Perguntas que têm resposta no dado.
Reginaldo, mas isso não é maquiar o resultado?
Pelo contrário. Um teste com perguntas fora do escopo do agente te dá um número injusto, baixo demais. Perguntas que refletem o uso real medem a qualidade que o usuário vai sentir. Avaliar bem é tão importante quanto construir bem.
O resultado: 90% (e o Fail que sobrou)
Rodei o MESMO test set (as 10 perguntas curadas, coerentes com o calendário) e o número saltou:
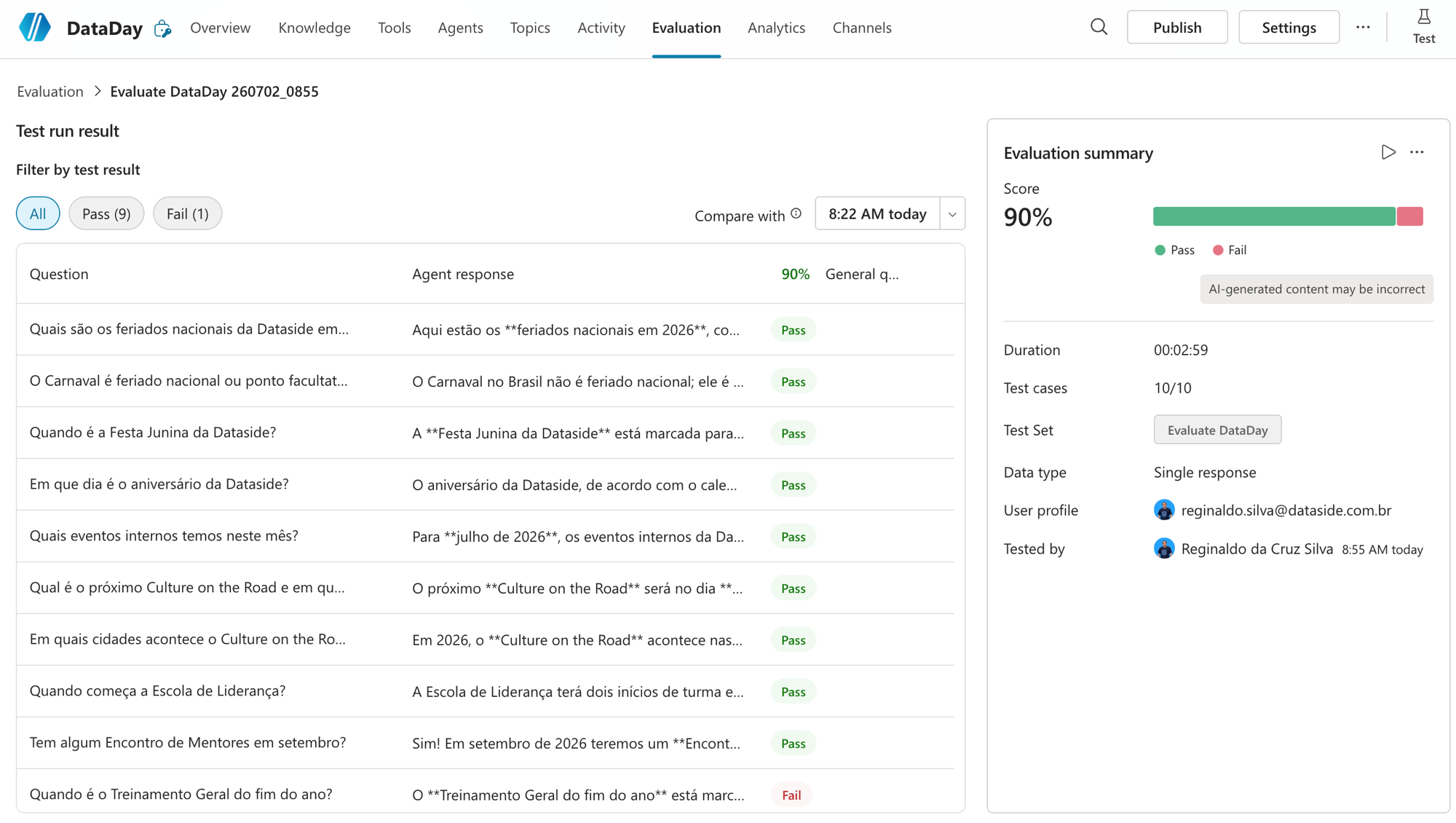
9 Pass, 1 Fail, 90%. As perguntas que antes davam "Not answered" (eventos do mês, próximo Culture on the Road, Mentores em setembro) agora passam com data e tudo. O juiz confirma: "All quality checks passed, resposta no tema, útil e embasada nos documentos".
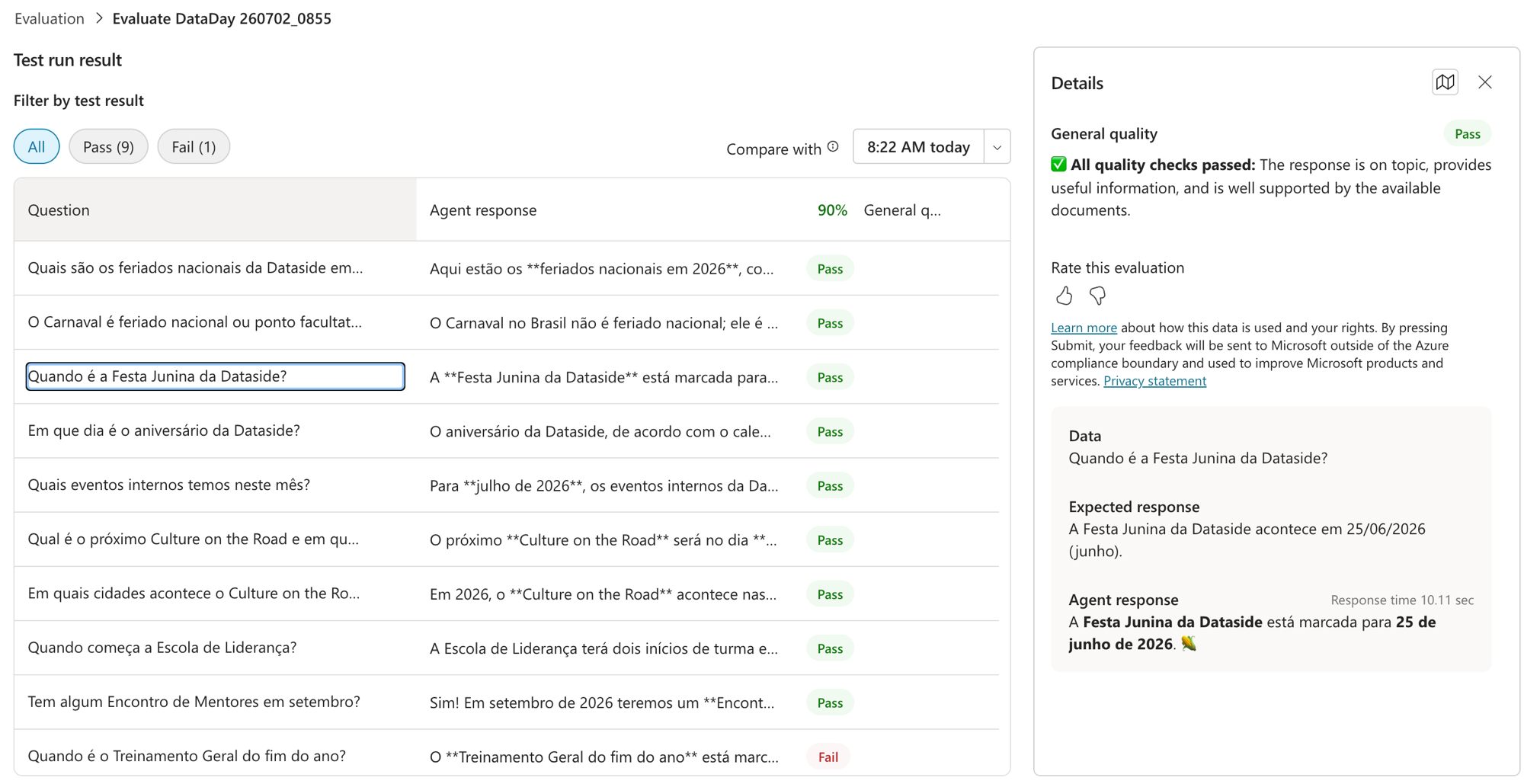
E o 1 Fail que sobrou? Foi o "Quando é o Treinamento Geral do fim do ano?". Esse é um caso de ambiguidade: no calendário existem dois Treinamentos Gerais (26/02 e 25/11), e "fim do ano" é interpretação. Ou seja, não é bug de retrieval, é pergunta ambígua. Serve de lembrete: 90% não é 100%, e tá tudo bem. O objetivo é subir a qualidade de forma medida, não perseguir nota cheia num teste sintético.
A lição de ouro
Se você levar uma coisa desse post, leve essa: dá pra melhorar muito sem trocar o modelo nem reescrever o agente. Uma tool certa (data), desligar o que atrapalha (Web Search) e um teste honesto (perguntas reais) levaram o DataDay de 40% a 90%. Foi ajuste de configuração e de avaliação, não de modelo.
E a segunda lição: metade da qualidade está em como você mede. Perguntas geradas automaticamente são ótimas pra começar, mas podem te dar um número injusto. Cure o seu test set com perguntas reais e o score passa a refletir o que o usuário vive.
No fim, agente bom é agente iterado: construir (post 3), medir (post 4) e melhorar medindo de novo (esse post). O Evaluation é o que transforma "acho que melhorei" em "melhorei de 40% pra 90%".
RESUMO
Saí de 40% pra 90% sem trocar o modelo de IA, só com ajustes de tool, configuração e teste.
Tool de data (Agent flow com utcNow + convertFromUtc): resolve "hoje / esta semana / próximo". Peça nas Instructions pra ele chamar a tool.
Web Search desligado: tira o ruído da internet e ajuda o agente a focar na fonte interna.
Set de perguntas curado: troquei as perguntas geradas automaticamente por perguntas reais e coerentes com o calendário. Avaliar bem importa tanto quanto construir bem.
A jornada não é linear (cheguei a regredir pra 30%); use o histórico e o Compare with pra guiar os ajustes.
Sobrou 1 Fail por ambiguidade da pergunta. 90% não é 100%, e está ótimo.
Lição de ouro: dá pra ir de 40% a 90% com tool + configuração + teste honesto, sem trocar o modelo.
E com isso a gente fecha a introdução básica da série: você já sabe onde o Copilot Studio vive, do que um agente é feito, como criar um do zero, como avaliar e como melhorar de forma medida. Daqui pra frente a gente aprofunda (SharePoint a fundo, conectar o Databricks, orquestração e mais). Bora juntos!
Referências:
https://learn.microsoft.com/en-us/microsoft-copilot-studio/analytics-agent-evaluation-overview
https://learn.microsoft.com/en-us/microsoft-copilot-studio/knowledge-copilot-studio
Fique bem e até a próxima.
#copilotstudio #microsoftai #evaluation #rag #agentes #ia #powerplatform #datainaction
Gostou? Tem mais no YouTube e no LinkedIn.